
Cea mai importantă publicație din Taiwan a enunțat astăzi știrile nVIDIA: au confirmat că compania a pre-rezervat procesele pe 5nm de la TSMC pentru a le folosi pentru plăcile grafice next-gen Hopper. Conform unui raport pe care l-am relatat deja, abordarea agresivă a AMD cu procesul pe 7nm a luat nVIDIA prin surprindere, iar pentru a gestiona chestiunea, aceștia au rezervat procesul pe 5nm al TSMC pentru plăcile grafice Hopper. În timp ce comanda TSMC este confirmată, am descoperit că nVIDIA o invită pe Samsung și pentru procesul lor de 5nm, așa că poate le vom vedea comenzile împărțite.
nVIDIA a pre-comandat capacitatea TSMC pe 5nm pentru plăcile grafice Hopper pentru 2021
Aceasta este o mare veste, deoarece, cu roadmap-ul actual, s-ar presupune că nVIDIA utilizează doar o generație pentru procesul pe 7nm (cu excepția cazului în care Hopper întârzie și ar pătrunde cu o arhitectură reîmprospătată Ampere, ceea ce trebuie să recunoaștem că este destul de posibil). Conform raportului pe care l-am acoperit deja, AMD a luat nVIDIA prin surprindere cu comanda lor pe 7nm, iar compania devine extrem de agresivă în a-și proteja creșterea viitoare. Dublarea pe procesul principal pe 5nm al TSMC este parte integrantă a acestei strategii.
Porțiunea relevantă a raportului Digitimes, via @chiakohua (și reprodusă cu permisiunea respectivului user):
Pentru plăcile next-gen bazate pe arhitectura Hopper, nVIDIA a rezervat deja capacitatea de producție pe 5nm a TSMC pentru 2021 și este în discuție și cu Samsung pentru comenzi de volum mai mic…
…Pentru a preveni AMD să crească din ce în ce mai mult, nVIDIA a decis să îi ajungă din urmă, chiar să depășească AMD, în adoptarea nodurilor EUV de 7nm și 5nm TSMC. (DigiTimes)
Rețineți că Hopper este doar un nume în acest moment, iar nVIDIA ar putea decide să numească Hopper orice altceva cu care să meargă înainte, dar avem confirmarea din partea companiei că rezervă capacitatea pe 5nm pentru arhitectura viitoare. Iată însă că, în timp ce nVIDIA a petrecut cel puțin câțiva ani înainte pe un singur nod, peisajul cu un AMD agresiv denotă că compania ar putea să nu aibă de ales.
Nu poate rămâne pe procesul de 7nm dacă AMD decide să treacă la 5nm încă o dată (ceea ce vor face). Dacă face acest lucru, s-ar diminua valoarea brandului său și s-ar îngreuna poziționarea ca lider în tehnologia plăcilor grafice. Soluția, așa cum transpare, este de a juca o carte puternică pre-rezervând capacitatea pe 5nm în avans – astfel încât AMD să nu o poată face. Aceasta este strategia, având în vedere că nVIDIA are disponibili mai mulți bani, iar TSMC nu-i va refuza, așteptându-ne să aibă mai mult succes în restabilirea lui nVIDIA în calitate de lider în industria plăcilor grafice.
Recapitulare: explorarea arhitecturii Hopper de la nVIDIA și a filozofiei MCM
Avertisment: utilizarea MCM în arhitectura Hopper nu este confirmată.
Arhitecturile nVIDIA sunt întotdeauna bazate pe pionieratul calculatoarelor și aceasta despre care discutăm provine tot de acolo. Arhitectura Hopper a nVIDIA provine de la Grace Hopper, care a fost una dintre pionierele informaticii și unul dintre primii programatori ai lui Harvard Mark 1 și inventatoarea primelor compilatoare. Ea a popularizat, de asemenea, ideea limbajelor de programare independente de mașină, care au dus la dezvoltarea COBOL – unul dintre primele limbaje de programare de nivel înalt care este încă utilizat în prezent. S-a înrolat în marina americană și a contribuit în timpul celui de-al doilea război mondial.

Un design bazat pe MCM este, fără îndoială, următorul pas în evoluția procesoarelor grafice, având în vedere că acum suntem limitați de mărimea reticulei majorității scanerelor EUV. Îmbunătățirile arhitecturale și designul MCM este următoarea frontieră logică și, întrucât AMD a realizat deja execuții pentru procesoare, are sens când spunem că plăcile grafice ar fi următorul pas în marele lor plan – ceea ce ar explică de ce nVIDIA ar dori să prindă startul în toate și să o ia înainte. Dezvăluirea a venit de la un cunoscut user twitter, iar postările au fost șterse până în prezent, dar nu înainte ca Twitterati să le ia și să le posteze (pe 3DCenter.org).
AMD s-a dovedit deja a fi excepțional de bună în crearea de produse bazate pe MCM. Seria Threadripper și Ryzen au dat peste cap piața HEDT. Aceștia au transformat singuri ceea ce era de obicei un produs cu 6 nuclee și foarte scump într-un combo cu 16 nuclee accesibil la preț folosind metoda MCM. Puterea serverelor și procesoarele Xeon au ajuns în sfârșit în mâinile consumatorilor obișnuiți, așa că de ce nu poate funcționa aceeași filozofie și pentru plăcile video? Suntem siguri că știți deja că nVIDIA poate folosi filozofia MCM pentru a bate dimensiunea reticulelor scanerelor și să construiască plăci grafice cu adevărat monstruoase care depășesc o suprafață netă de 1000 mm², dar există și alte avantaje?
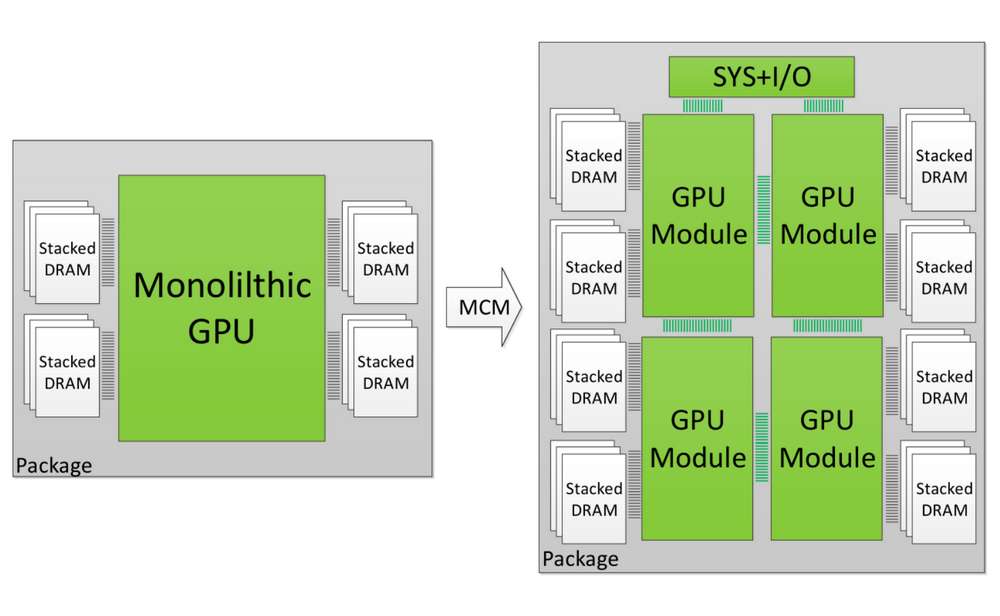
Ei bine, teoretic vorbind, ar trebui să funcționeze mai bine în ceea ce privește plăcile care sunt dispozitive în paralel decât pentru procesoarele care sunt dispozitive în serie. Nu numai, dar te uiți și la câștigurile masive de randament în trecerea la o abordare bazată pe MCM în loc de un cip monolitic. Un singur cip uriaș are randamente abisale, este scump de produs și are de obicei risipă mare. Cipurile multiple, care însumează aceeași dimensiune a cașetei, ar oferi creșteri ale randamentului din start. Acesta este un argument excelent în favoarea plăcii grafice Hopper de la nVIDIA.
Folosind instrumentul Silicon Edge cercetătorii au putut face câteva aproximări grosso modo și au descoperit câștiguri instantanee de randament. Luând un cip care măsoară 484 mm² (de exemplu, Vega 64), ceea ce echivalează cu 22 mm pe 22 mm. Împărțirea acestui cip monolitic în 4x11mm pe 11 mm vă oferă aceeași suprafață netă (484mm²) și va avea ca rezultat și câștig de randament. Cât? Sa vedem. Conform aproximării, o cașetă de 300 mm ar trebui să poată produce 114 cipuri monolitice (22×22) sau 491 cipuri mai mici (11×11). Deoarece avem nevoie de 4 cipuri mai mici, care să egaleze o parte monolitică, ajungem la 122 de 484 mm² cipuri MCM. Acesta este un câștig de 7,6%.
Cu cât sunt mai mari cipurile, cu atât și randamentele. Limita superioară a tehnicilor litografice (cu randamente rezonabile) este de aproximativ 815mm². Pe o singură cașetă de 300 mm, putem obține aproximativ 64 dintre acestea (28.55×28.55) sau 285 cipuri mai mici (14.27×14.27). Aceasta ne oferă un număr de 71 de cipuri pe bază de MCM pentru o creștere a randamentului de aproximativ 11%. Acuma, dezvăluind complet, aceasta este o aproximare foarte în mare și nu ține cont de mai mulți factori, cum ar fi randamentul în pachete, cipul dreptunghiular și alte optimizări ale plăcii, dar ideea de bază ține bine. În schimb, nu ia în considerare câștigurile crescute prin pierderile înregistrate – un cip monolitic defectuos de 815 mm² este mult mai risipitor decât unul singur de 203 mm²! Acest lucru înseamnă că această abordare are avantajul suplimentar de a reduce la minimum impactul cipurilor defecte – ceea ce va adăuga la aceste numere de randament odată ce factorizați cipurile inutilizabile.
Ca să scurtăm povestea, nVIDIA este perfect capabilă să creeze o placă grafică bazată pe MCM și ar putea chiar să obțină câteva avantaje serioase de randament dacă ar alege să meargă înainte cu aceasta pentru plăcile Hopper. Având în vedere că nodul de 7nm intră acum într-un stadiu matur cu EUV, gravurile vor fi foarte clare și ar trebui să poată susține un concept ca acesta cu ușurință, dar sunt încă limitate de mărimea reticulului. Trecerea la un design bazat pe MCM ar permite nVIDIA să creeze plăci monstruoase cu o dimensiune netă mai mare de 815mm² (cerul este limita cu MCM – așa cum a demonstrat-o AMD)! Așadar, dacă dorește să continue tendința sa de creștere a performanței neliniare, care a reușit să aibă atât de mult succes, s-ar putea să nu aibă altă opțiune decât să o adopte.